
Experiment
Building a Local Agentic AI Development Workflow
A local-first AI development workflow evolved from prompt-only experimentation into a structured system for validation, orchestration, retrieval, observability, and human oversight.
Why This Exists
I wanted to explore whether AI-assisted software development could become more reliable, observable, and operationally grounded without relying entirely on commercial AI platforms or cloud-hosted infrastructure.
The goal was not simply to experiment with AI coding tools. The larger objective was to build a repeatable local-first workflow that combined AI generation with deterministic validation, structured orchestration, and human oversight.
This project became a broader exploration of:
- Local AI infrastructure
- Multi-agent coordination
- Evaluation-driven development
- Governance and validation systems
- Human-centered AI engineering workflows
The work also helped me better understand the tradeoffs organizations face when security, privacy, or operational constraints limit the use of commercial AI services.
Context
Most modern AI coding workflows rely heavily on:
- Cloud-hosted models
- Prompt-only orchestration
- Vendor-controlled infrastructure
- Limited validation and observability
While these systems are powerful, they also create operational concerns around:
- Reliability
- Repeatability
- Governance
- Security
- Transparency
- Cost control
I wanted to explore whether a more structured engineering approach could improve the stability and trustworthiness of AI-assisted development workflows.
Approach
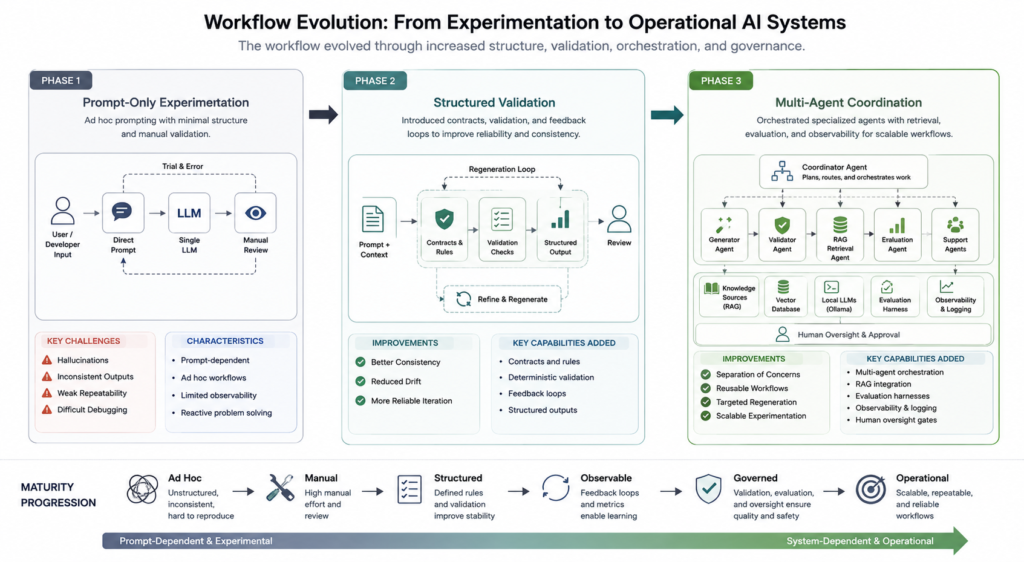
The workflow evolved through several phases.
Phase 1 – Prompt-Only Experimentation
Initial workflows relied heavily on direct prompting and manual review.
This created several recurring problems:
- Inconsistent outputs
- Hallucinated structures
- Weak repeatability
- Difficult debugging
Phase 2 – Structured Validation
Contract-driven validation layers were introduced to improve output consistency and reduce drift.
This shifted the workflow from:
Generate and hope
to:
Generate, validate, refine.
Phase 3 – Multi-Agent Coordination
Additional orchestration layers introduced:
- Specialized agent roles
- Separation of concerns
- Targeted regeneration cycles
- Structured evaluation loops
One of the most important discoveries during this phase was realizing that orchestration alone was not enough. The system also needed clear definitions of quality.
To improve this, I developed iterative evaluation criteria and scoring rubrics through repeated testing and refinement. In some cases, I even used AI-assisted interviews to help externalize and formalize what “good” output actually meant for different workflows.
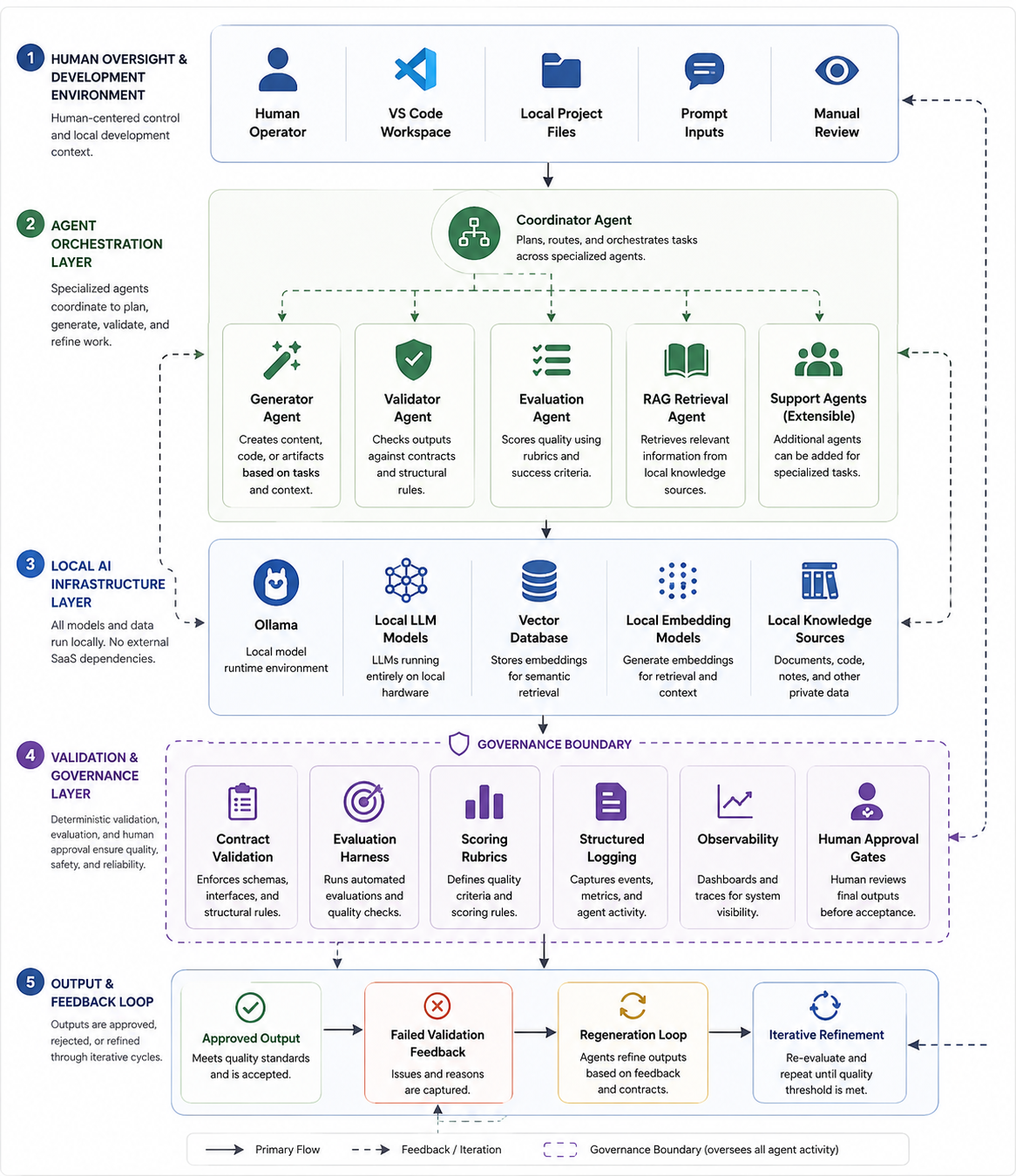
System or Process View
Core Components
- Local LLM infrastructure via Ollama
- VS Code agentic coding workflows
- Contract-driven validators
- Multi-agent orchestration
- RAG-based retrieval systems
- Evaluation harnesses
- Structured logging and observability
Architectural Principles
- Deterministic systems before generative systems
- Governance before autonomy
- Human review over blind execution
- Modular components over monolithic agents
- Clear operational boundaries between agents
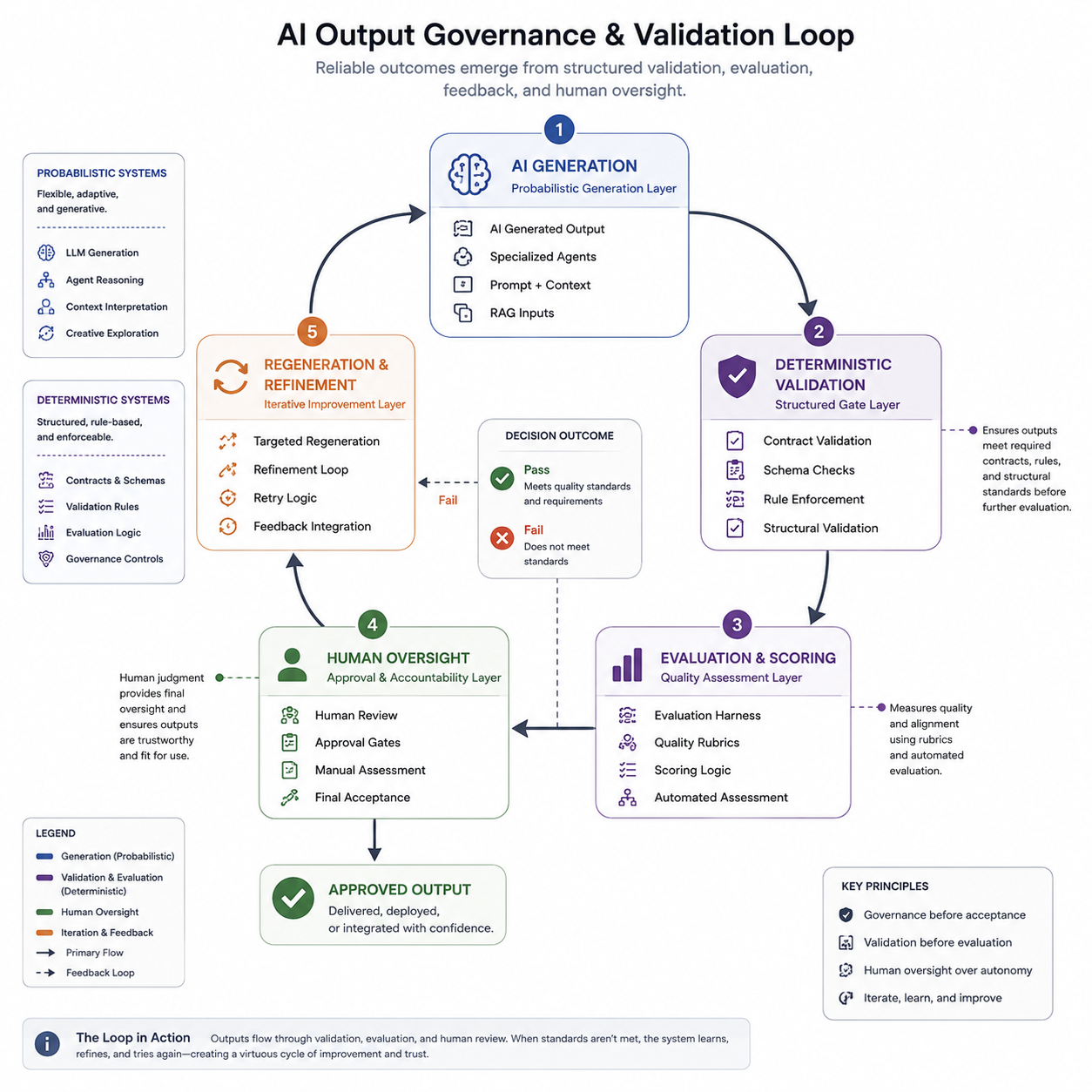
What Worked
Several patterns consistently improved reliability and workflow quality:
- Deterministic validation dramatically reduced hallucinations and structural drift
- Multi-agent separation of concerns improved maintainability
- Evaluation harnesses made iteration cycles more measurable
- Local-first infrastructure reduced operational cost for experimentation
- Structured observability improved debugging and refinement
The resulting workflow also became reusable across additional projects and experiments, creating a foundation for future AI exploration work.
What Did Not Work
Several challenges emerged throughout development:
- Local hardware introduced significant performance limitations
- Context window management became increasingly difficult as orchestration complexity grew
- Over-engineering became a recurring risk
- Different local models behaved inconsistently under similar prompts and evaluation conditions
Running local LLMs entirely on consumer hardware also highlighted practical tradeoffs between privacy, speed, and output quality. Tasks that take seconds using commercial infrastructure or server-grade hardware could take several minutes locally.
Even with those limitations, the workflow remained valuable as an experimentation and learning environment where the primary success criteria was understanding what worked, what failed, and why.
Lessons Learned
This project reinforced several important ideas:
- Prompt engineering is not architecture
- Reliability emerges from systems, not prompts alone
- Validation matters more than raw model size
- AI workflows require operational discipline
- Human-centered design principles apply to AI tooling itself
Most importantly, building a local-first workflow created a safe environment for experimentation without depending entirely on commercial platforms, hidden system behavior, or ongoing API costs.
That freedom made it easier to test ideas, iterate quickly, fail safely, and better understand how AI systems can be designed more intentionally.
What I Would Do Next
Future iterations would likely focus on:
- Distributed local inference infrastructure
- Improved orchestration observability
- More advanced evaluation frameworks
- Better memory and context management
- Expanded reusable agent libraries
- Stronger governance and audit tooling